Data Handler
The dataHandler feature has been deprecated since version v3.3.0. We recommend using the more sophisticated stepHandler instead.
For help with migration:
- Use our Migration GPT for automated guidance
- Contact our support team at [email protected]
Use our dataHandler feature on top of our cleaning functions to solve complex and complicated import scenarios. Take advantage of the advanced data access directly after the upload or after the mapping to customize your importer to suit your requirements.
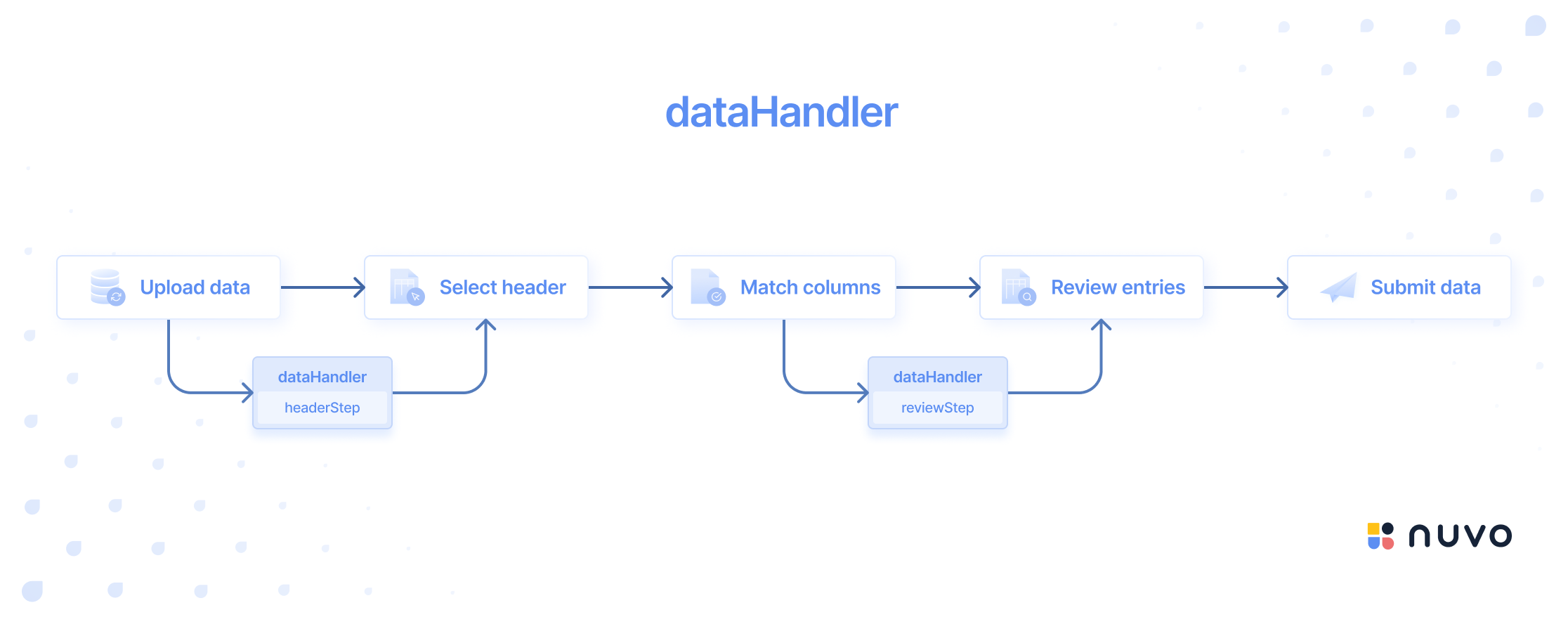
| Description | The dataHandler is a powerful tool that can be executed before the “Header Selection”- and/or “Review Entries” step, providing access to the original data and its metadata as well as enabling you to add/remove columns and rows. It can be configured to run based on your needs. |
| With the dataHandler function, you can solve complex data manipulation scenarios, such as transposing data, merging and splitting columns, joining sheets, de-nesting data, and more. Unlike other cleaning functions that iterate through every entry, the dataHandler function works on the entire data at once, giving you complete control over input data. | |
| In addition, with the dataHandler function, you can add, delete, and modify columns and rows in the data, providing even greater flexibility in data manipulation. | |
| Whether you need to transform a single column or an entire dataset, the dataHandler function provides the flexibility and power required to do the job effectively and efficiently. | |
| Run Event | The execution of this function can occur before the “Header Selection”- or before the “Review Entries” step, or even both, depending on the configuration. |
| Parameter | modifier: The modifier parameter is a function that enables modifying the data by adding or deleting columns and rows. This function allows customization of the data per your requirements. The modifier function includes the following sub-functions:
|
data: The data parameter is a data structure that provides detailed information about the imported file(s). It includes attributes such as the file size, file name, and file extension, as well as the original data of the input.
| |
logs: The logs contain details about the mappings as well as the custom-added columns and options during the mapping step.
|
Modifier
- Add a row
- Remove a row
- Add a column
- Remove a column
- Access (meta)data
| headerStep: | index: Specifies the position in the data where the new row will be inserted. If you pass an integer value for the index, the new row will be added to that specific index. If no index is passed or the index is null, a new row will be created at the end of the data. |
data: Comprises an array of arrays, where each inner array represents a new row of values to be added. | |
| reviewStep: | index: Specifies the position in the data where the new row will be inserted. If you pass an integer value for the index, the new row will be added to that specific index. If no index is passed or the index is null, a new row will be created at the end of the data. |
data: The data for the review step can have two formats based on your use case:
|
It should be noted that the addRow() function allows multiple rows to be added to the record at once.
dataHandler={{
headerStep: async (modifier, data) => {
// Adding a row as a 2D array
modifier.addRow({
index: 0,
data: [["Max", "Jordan"]],
});
},
reviewStep: async (modifier, data, logs) => {
// Adding a row without an error
modifier.addRow({
index: 0,
data: [{ column_key: "Hans" }],
});
// Adding a row with an error
modifier.addRow({
index: 1,
data: [
{
column_key: {
value: "Charlie",
info: [
{
message: "This cell was automatically added.",
level: "info",
},
],
},
},
],
});
},
}}
| headerStep: | index: Specifies the position in the dataset where the row will be removed. If you pass an integer value for the index, the row will be removed at that specific index. Nothing is changed if no index is passed or the index is null. |
| reviewStep: | index: Specifies the position in the dataset where the row will be removed. If you pass an integer value for the index, the row will be removed at that specific index. Nothing is changed if no index is passed or the index is null. |
dataHandler={{
headerStep: async (modifier, data) => {
modifier.removeRow(index);
},
reviewStep: async (modifier, data, logs) => {
modifier.removeRow(index);
}
}}
| headerStep: | label: This representing the name of the column being added. The label parameter is required and must be specified for the function to work correctly. |
| reviewStep: | key: This parameter is mandatory and serves as the unique identifier for the newly added column. |
label: This parameter is mandatory and represents the name of the new column. | |
columnType: This parameter is required and specifies the data type for the new column. | |
validations: This parameter is optional and can be used to apply any desired validations to the new column. For more information on the supported validations, please consult the validations section of our documentation. | |
hidden: This parameter is optional (default: false) and specifies whether that column is visible to users during the "Review Entries" step. | |
disabled: This parameter is optional (default: false) and specifies whether users can edit entries in that column during the "Review Entries" step. |
dataHandler={{
headerStep: async (modifier, data) => {
modifier.addColumn({ label: "column_label" });
},
reviewStep: async (modifier, data, logs) => {
modifier.addColumn({
key: "column_key",
label: "column_label",
columnType: "string",
validations: [{ validate: "required" }],
hidden: false,
disabled: false
});
}
}}
| headerStep: | index: This is an integer representing the position of the column being removed. |
| reviewStep: | column_key: This is a string that represents the key of the column being removed. |
dataHandler={{
headerStep: async (modifier, data) => {
modifier.removeColumn(index);
},
reviewStep: async (modifier, data, logs) => {
modifier.removeColumn(column_key);
}
}}
| headerStep: | data: This refers to the original dataset that the user uploaded. This dataset is always represented as a 2D array, where each inner array represents the content of a single sheet. Accessing the original data allows you to transform and rearrange the uploaded content to suit your import process more effectively. If needed, you can also access and/or save the file name, file size, file extension, and the uploaded raw data. The 2D array structure of the data allows you to access and manipulate individual sheets within a larger dataset easily. This can be particularly useful when working with large or complex datasets that contain multiple sheets. |
fileSize: Size of the uploaded file in mb | |
fileType: Type of the uploaded file | |
fileName: Name of the uploaded file | |
sheetName: Sheet name in case of an uploaded .xls(x) | |
data: 2d array representing the data that was uploaded by the user | |
| reviewStep: | data: This refers to the dataset mapped and transformed by the system into the desired output format. By working with the transformed data, you can review and validate the user's mapping as well as the imported data in your preferred format and make any necessary adjustments or corrections to the target data schema and the content before finalizing their output. |
dataHandler={{
headerStep: async (modifier, data) => {
console.log(data[0].data);
console.log(data[0].fileSize);
console.log(data[0].fileType);
console.log(data[0].fileName);
console.log(data[0].sheetName);
},
reviewStep: async (modifier, data, logs) => {
console.log(data);
},
}}
Returning data
The dataHandler enables you to return the complete data set after making modifications. It offers the flexibility to choose whether or not to return the modified data. If you decide to return the data, the modifier operations will be applied to the returned data. Alternatively, if you opt not to return the data, the modifier operations will be directly applied to the source data.
Moreover, the dataHandler allows you to obtain the data in two distinct formats for each stage. This feature empowers you to select the format that aligns best with your specific use case. You can also return a single or multiple sheets within the headerStep function.
| headerStep: | You can return the data in one of two formats, single or multiple sheets:
|
| reviewStep: | You can provide the data in one of two formats, with errors or without errors:
|
| It is important to ensure that the keys of your JSON data should match the keys of the target data model (TDM). |
- headerStep
- reviewStep
Returning a single sheet:
dataHandler = {
headerStep: async (modifier, data) => {
// Your custom logic
// Option 1: Return data as a 2D array
return [
["id", "name"],
["12345", "Jason"],
["67890", "Max"],
];
// Option 2: Return data as an array of objects
return [
{ id: 12345, name: "Jason" },
{ id: 67890, name: "Max" },
];
},
};
Returning multiple sheets:
dataHandler = {
headerStep: async (modifier, data) => {
// Your custom logic
// NOTE: data can be in different formats (2D array & array of objects)
return [
{
fileName: "Customers",
sheetName: "Internal",
data: [
["id", "name"],
["12345", "Jason"],
],
},
{
fileName: "Products",
sheetName: "Best sellers",
data: [
{ id: 12, quantity: 24 },
{ id: 13, quantity: 88 },
],
},
];
},
};
Returning data without errors:
dataHandler={{
reviewStep: async (modifier, data, logs) => {
const newData = data;
newData.push(
{ id: 12345, name: "Jason" },
{ id: 67890, name: "Max" }
);
return newData;
},
}}
Returning data with errors:
dataHandler={{
reviewStep: async (modifier, data, logs) => {
const newData = data;
newData.push(
{
id: {
value: 12345,
info: [
{
message: "Invalid id",
level: "error",
},
],
},
name: {
value: "Jason",
info: [
{
message: "This user does not exist",
level: "error",
},
],
},
},
{
id: { value: 12345 },
name: { value: "Max" },
}
);
return newData;
},
}}
Logs example
{
"mappings": [
{
"sourceColumn": "Company Identification Number",
"targetColumn": "company_code"
},
{
"sourceColumn": "Organisation",
"targetColumn": "company_name"
},
{
"sourceColumn": "Website",
"targetColumn": "domain_name"
},
{
"sourceColumn": "Address",
"targetColumn": "adress"
},
{
"sourceColumn": "Area",
"targetColumn": "region"
},
{
"sourceColumn": "Deal Value",
"targetColumn": "deal_size"
},
{
"sourceColumn": "Status",
"targetColumn": "deal_status"
},
{
"sourceColumn": "Pipeline",
"targetColumn": "pipeline"
},
{
"sourceColumn": "Expenditures",
"targetColumn": "costs"
},
{
"sourceColumn": "Active",
"targetColumn": "deal_ongoing"
},
{
"sourceColumn": "",
"targetColumn": "full_name"
}
],
"columns": {
"addedColumns": [
{
"label": "Revenue",
"key": "revenue",
"columnType": "currency_eur"
}
],
"addedOptions": [
{
"columnKey": "deal_stage",
"dropdownOptions": [
{
"label": "Done",
"value": "done",
"type": "string"
}
]
}
]
}
}
Implementation example
In the given example, we display how to iterate through the data after the mapping with the reviewStep function. We implemented a logic that fills the addresscolumn by merging thestreet, city, and countrycolumns if these three columns contain data. We then remove thestreet, city, and country columns from the output schema.
- React
- Angular
- Vue
- JavaScript
<NuvoImporter
licenseKey="Your License Key"
settings={{
developerMode: true,
identifier: "product_data",
columns: [
{
key: "full_name",
label: "Full name",
columnType: "string",
},
{
key: "street",
label: "Street",
columnType: "string",
},
{
key: "city",
label: "City",
columnType: "string",
},
{
key: "country",
label: "Country",
columnType: "string",
},
{
key: "Address",
label: "Address",
columnType: "string",
},
],
}}
dataHandler={{
reviewStep: async (modifier, data, logs) => {
const dataLength = data.length;
const newData = data;
for (let i = 0; i < dataLength; i++) {
const element = data[i];
if (!element.Address && element.street && element.city && element.country) {
newData[i].Address = `${element.street}, ${element.city}, ${element.country}`;
}
}
modifier.removeColumn("street");
modifier.removeColumn("city");
modifier.removeColumn("country");
return newData;
},
}}
/>
- Add the NuvoImporter module to the file
app.module.ts.
import { NuvoImporterModule } from "@getnuvo/importer-angular";
@NgModule({
declarations: [AppComponent],
imports: [NuvoImporterModule, BrowserModule, AppRoutingModule],
providers: [],
bootstrap: [AppComponent],
})
export class AppModule {}
- Add the nuvo component inside the HTML file
app.component.html.
<nuvo-importer [licenseKey]="licenseKey" [settings]="settings" [dataHandler]="dataHandler" />
- Define the property inside the component file
app.component.ts.
export class AppComponent implements OnInit {
settings!: SettingsAPI;
licenseKey!: string;
dataHandler!: DataHandler;
ngOnInit(): void {
this.licenseKey = "Your license key";
this.settings = {
identifier: "product_data",
developerMode: true,
columns: [{
key: "full_name",
label: "Full name",
columnType: "string",
},
{
key: "street",
label: "Street",
columnType: "string",
},
{
key: "city",
label: "City",
columnType: "string",
},
{
key: "country",
label: "Country",
columnType: "string",
},
{
key: "Address",
label: "Address",
columnType: "string",
}
],
};
this.dataHandler = {
reviewStep: async (modifier, data, logs) => {
const dataLength = data.length;
const newData = data;
for (let i = 0; i < dataLength; i++) {
const element = data[i];
if (!element.Address && element.street && element.city && element.country) {
newData[i].Address = `${element.street}, ${element.city}, ${element.country}`;
}
}
modifier.removeColumn("street");
modifier.removeColumn("city");
modifier.removeColumn("country");
return newData;
},
}
}
}
We're phasing out support for Vue 2. If you're still using Vue 2, you can use "nuvo-vuejs" v2.9 or lower.
- Add the nuvo component inside the
<template>tag in the fileApp.vue.
<template>
<div id="app">
<NuvoImporter :settings="settings" :licenseKey="licenseKey" :dataHandler="dataHandler" />
</div>
</template>
- Define the property inside the
<script>tag in the component file.
export default {
name: "App",
components: {
NuvoImporter,
},
setup() {
const settings = {
developerMode: true,
identifier: "product_data",
columns: [
{
key: "full_name",
label: "Full name",
columnType: "string",
},
{
key: "street",
label: "Street",
columnType: "string",
},
{
key: "city",
label: "City",
columnType: "string",
},
{
key: "country",
label: "Country",
columnType: "string",
},
{
key: "Address",
label: "Address",
columnType: "string",
},
],
};
return { settings };
},
data: () => {
return {
licenseKey: "Your License Key",
dataHandler: {
reviewStep: async (modifier, data, logs) => {
const dataLength = data.length;
const newData = data;
for (let i = 0; i < dataLength; i++) {
const element = data[i];
if (!element.Address && element.street && element.city && element.country) {
newData[i].Address = `${element.street}, ${element.city}, ${element.country}`;
}
}
modifier.removeColumn("street");
modifier.removeColumn("city");
modifier.removeColumn("country");
return newData;
},
},
};
},
};
Our vanilla JS syntax has changed since v2.9. If you use v2.8 or lower, please migrate to the latest version by following our migration guide.
<div class="nuvo-container" />
<script type="module">
import { launchNuvoImporter } from "@getnuvo/importer-vanilla-js";
launchNuvoImporter(".nuvo-container", {
licenseKey: "Your License Key",
settings: {
developerMode: true,
identifier: "product_data",
columns: [
{
key: "full_name",
label: "Full name",
columnType: "string",
},
{
key: "street",
label: "Street",
columnType: "string",
},
{
key: "city",
label: "City",
columnType: "string",
},
{
key: "country",
label: "Country",
columnType: "string",
},
{
key: "Address",
label: "Address",
columnType: "string",
},
],
},
dataHandler: {
reviewStep: async (modifier, data, logs) => {
const dataLength = data.length;
const newData = data;
for (let i = 0; i < dataLength; i++) {
const element = data[i];
if (!element.Address && element.street && element.city && element.country) {
newData[i].Address = `${element.street}, ${element.city}, ${element.country}`;
}
}
modifier.removeColumn("street");
modifier.removeColumn("city");
modifier.removeColumn("country");
return newData;
},
},
onResults: (result, errors, complete, logs) => {
complete();
},
});
</script>
If you’re interested in exploring additional use cases, kindly navigate to our knowledge base available on the user platform.